provenance¶


provenance is a Python library for function-level caching and provenance that aids in
creating Parsimonious Pythonic Pipelines™. By wrapping functions in the provenance
decorator computed results are cached across various tiered stores (disk, S3, SFTP) and
provenance (i.e. lineage) information is tracked
and stored in an artifact repository. A central artifact repository can be used to enable
production pipelines, team collaboration, and reproducible results. The library is general
purpose but was built with machine learning pipelines in mind. By leveraging the fantastic
joblib library object serialization is optimized for numpy and other PyData libraries.
What that means in practice is that you can easily keep track of how artifacts (models,
features, or any object or file) are created, where they are used, and have a central place
to store and share these artifacts. This basic plumbing is required (or at least desired!)
in any machine learning pipeline and project. provenance can be used standalone along with
a build server to run pipelines or in conjunction with more advanced workflow systems
(e.g. Airflow, Luigi).
Example¶
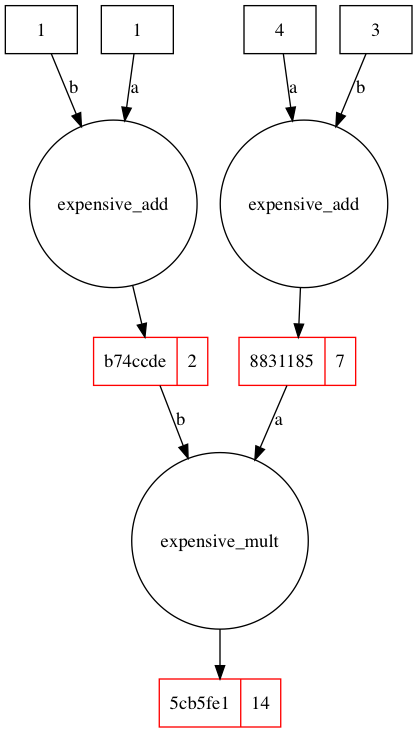
For an explanation of this example please see the Introductory Guide.
import provenance as p
p.load_config(...)
import time
@p.provenance()
def expensive_add(a, b):
time.sleep(2)
return a + b
@p.provenance()
def expensive_mult(a, b):
time.sleep(2)
return a * b
a1 = expensive_add(4, 3)
a2 = expensive_add(1, 1)
result = expensive_mult(a1, a2)
vis.visualize_lineage(result)
Installation¶
For the base functionality:
pip install provenance
For the visualization module (which requires graphviz to be installed):
pip install provenance[vis]
For the SFTP store:
pip install provenance[sftp]
For everything all at once:
pip install provenance[all]